
1、编程方式
Hadoop的MapReduce在计算数据时,计算过程必须要转化为Map和Reduce两个过程,从而难以描述复杂的数据处理过程;而Spark的计算模型不局限于Map和Reduce操作,还提供了多种数据集的操作类型,编程模型比MapReduce更加灵活。
2、数据存储
Hadoop的 MapReduce进行计算时,每次产生的中间结果都是存储在本地磁盘中;而
Spark在计算时产生的中间结果存储在内存中。
3、数据处理
Hadoop在每次执行数据处理时,都需要从磁盘中加载数据,导致磁盘的I/O开销较大;而Spark在执行数据处理时,只需要将数据加载到内存中,之后直接在内存中加载中间结果数据集即可,减少了磁盘的1O开销。
4、数据容错
MapReduce计算的中间结果数据保存在磁盘中,并且 Hadoop框架底层实现了备份机制,从而保证了数据容错;同样 Spark RDD实现了基于 Lineage的容错机制和设置检查点的容错机制,弥补了数据在内存处理时断电丢失的问题。
在Spark与Hadoop的性能对比中,较为明显的缺陷是Hadoop中的MapReduce计算延迟较高,无法胜任当下爆发式的数据增长所要求的实时、快速计算的需求。
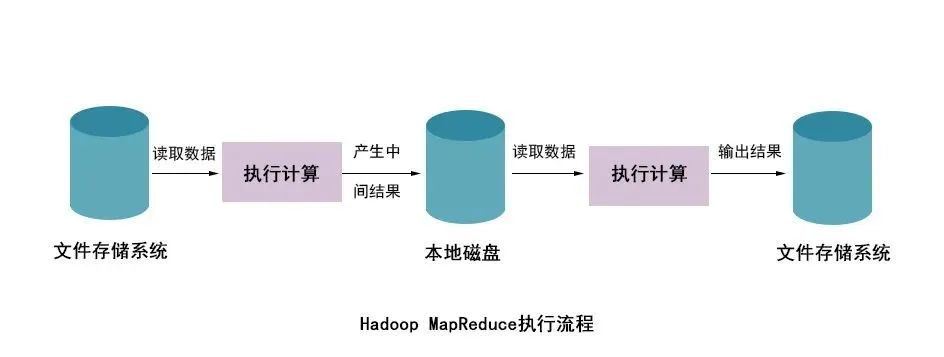
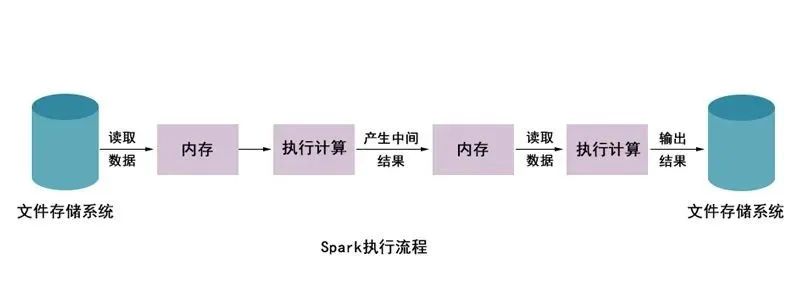
从上图可以看出,使用Hadoop MapReduce进行计算时,每次计算产生的中间结果都需要从磁盘中读取并写入,大大增加了磁盘的I/O开销,而使用Spark进行计算时,需要先将磁盘中的数据读取到内存中,产生的数据不再写入磁盘,直接在内存中迭代处理,这样就避免了从磁盘中频繁读取数据造成的不必要开销。通过官方计算测试,Hadoop与Spark执行逻辑回归所需的时间对比,如图所示。
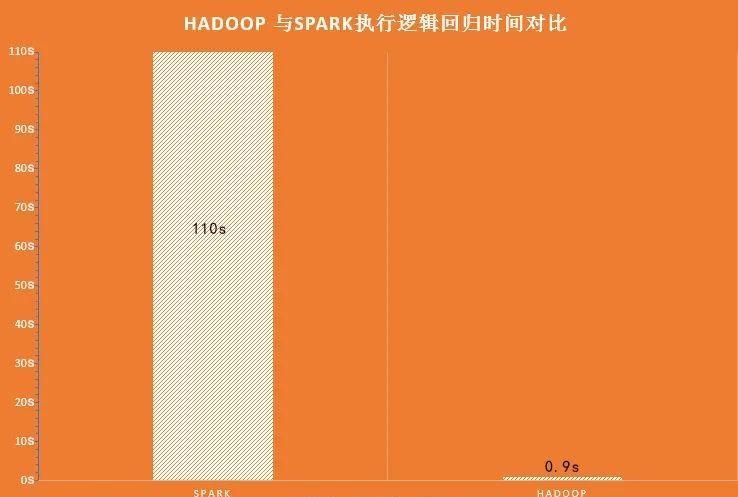
从上图可以看出,Hadoop与Spark执行的所需时间相差超过100倍。












